In the realm of machine learning, loss functions are pivotal. They are the mechanisms through which models learn and improve, providing a measure of how well (or poorly) a model performs. Understanding loss functions is essential for anyone delving into data science or machine learning. Let’s explore what loss functions are, why they matter, and some of the most common types.
What is a Loss Function?
A loss function, also known as a cost function or objective function, quantifies the difference between the predicted values and the actual values. It essentially tells us how far off our model’s predictions are from the true outcomes. The goal of training a machine learning model is to find the parameters (weights) that minimize this loss.
Why Are Loss Functions Important?
Loss functions guide the optimization process. During training, algorithms adjust the model’s parameters to minimize the loss, which ideally leads to better predictions. Without a well-defined loss function, it would be impossible to evaluate and improve a model’s performance.
Common Types of Loss Functions
- Mean Squared Error (MSE):
- Use Case: Regression tasks.
- Description: MSE measures the average squared difference between the predicted and actual values. It penalizes larger errors more severely, making it useful for tasks where outliers are significant.
- Formula:

- Mean Absolute Error (MAE):
- Use Case: Regression tasks.
- Description: MAE calculates the average absolute differences between predicted and actual values. It treats all errors equally, providing a more robust measure when dealing with outliers.
- Formula:

- Binary Cross-Entropy (Log Loss):
- Use Case: Binary classification.
- Description: Binary cross-entropy measures the performance of a classification model whose output is a probability value between 0 and 1. It is widely used for binary classification tasks.
- Formula:
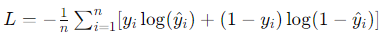
- Categorical Cross-Entropy:
- Use Case: Multi-class classification.
- Description: This loss function is an extension of binary cross-entropy for multi-class classification problems. It evaluates the predicted probability distribution over multiple classes.
- Formula:
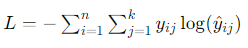
- Hinge Loss:
- Use Case: Support vector machines (SVMs).
- Description: Hinge loss is used for training classifiers, particularly SVMs. It ensures that the predictions are not only correct but also confidently so.
- Formula:
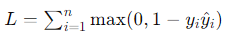
Choosing the Right Loss Function
Selecting the appropriate loss function depends on the type of problem you’re solving (regression vs. classification), the nature of your data, and the specific requirements of your task. For instance, while MSE is popular for regression, it might not be suitable for all scenarios, especially if your data has many outliers.
Conclusion
Loss functions are integral to the success of machine learning models. They not only guide the training process but also directly impact the accuracy and reliability of the predictions. Understanding different types of loss functions and their applications can significantly enhance your ability to build and refine effective machine learning models.
Whether you are predicting house prices, classifying images, or recommending products, the right loss function is the key to unlocking the full potential of your machine learning algorithms.